Analytics & Performance
First-party visitor data, real-user Web Vitals, and search insight all captured directly into the buyer's Postgres, joined to the conversion data without an integration bridge. What the standard analytics stack cannot answer, the architectural cost of owning the data instead of renting access to it, and the kind of question this design lets a buyer ask.
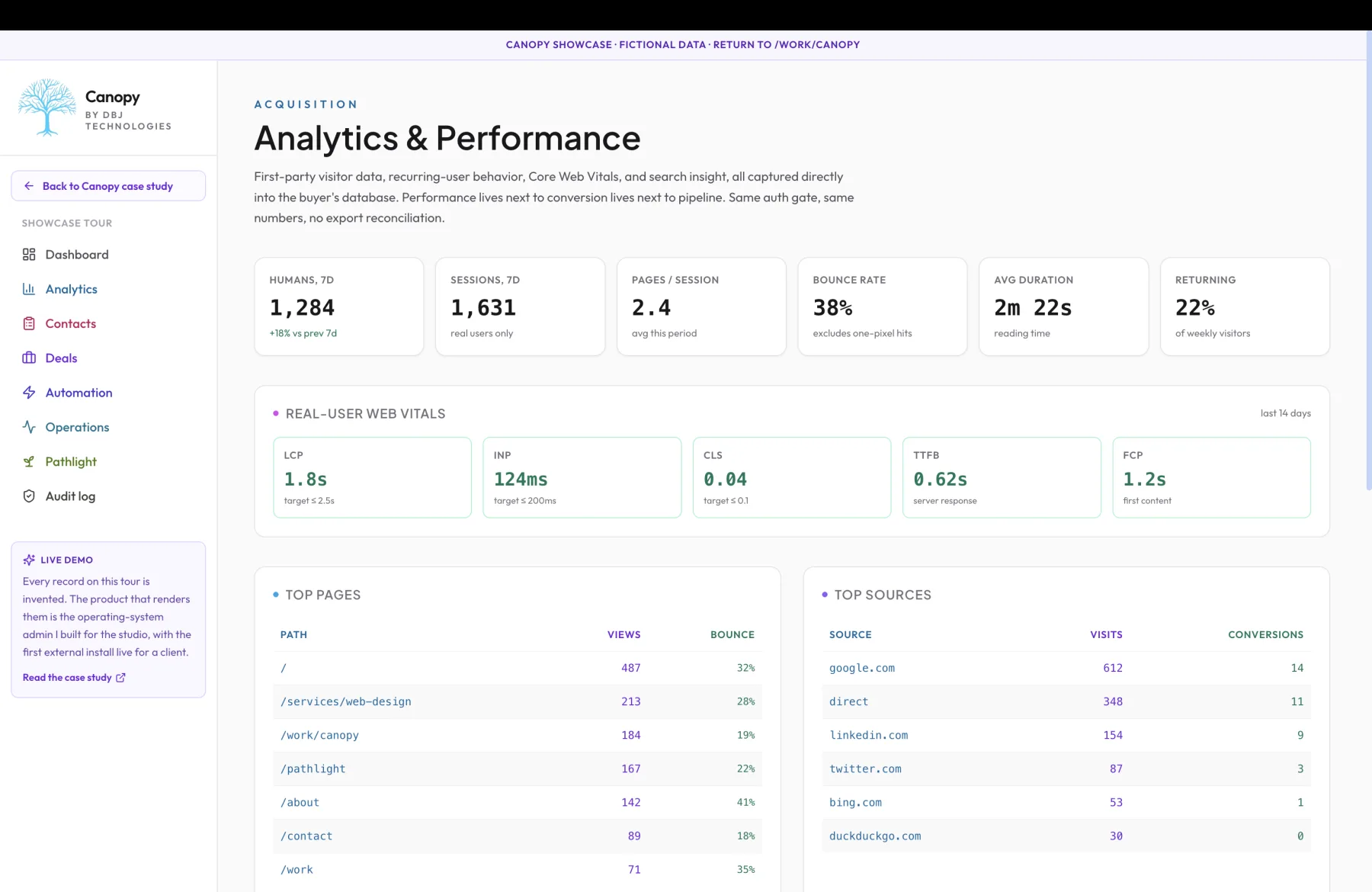
The question I asked first when shaping the analytics surface: what changes when the visitor data and the conversion data live in the same database under the same auth gate. The answer turns out to be the kind of question the buyer can ask. With the standard stack, a buyer can ask 'what was my bounce rate last week.' That is what third-party analytics platforms are good at; that is what they sell. A buyer cannot ask 'of the prospects who became deals last quarter, which marketing source did they originate from, and what was their median time from first visit to closed-won.' That second question requires joining two systems that the SaaS contract does not let you join, and the export reconciliation that pretends to support it never quite agrees between tools. Bounce rate is a gauge; the source-to-deal join is a question about whether marketing actually worked. The buyer who is trying to decide where to spend their next dollar needs the second question answered, and the standard stack cannot answer it. I considered the standard stack: a third-party analytics SDK on the front end, the CRM accessed through its public API, a webhook bridge between the two, an attribution tool layered over the bridge to do the source-to-deal joins, a dashboard layered over the attribution tool to render the joins. Five products in the path, four contracts the buyer is paying for, three integrations that have to stay in sync. I rejected the stack for the same reason I reject most multi-vendor solutions: every layer of it rents access to the buyer's data back to the buyer, and the bridge is what breaks first. When a vendor changes their API, when a pricing tier is sunset, when a product is acquired and the integration goes EOL, the bridge breaks and the buyer's view of their own funnel goes dark until they can rebuild it. The cost compounds across vendors. The data fragments across data centers. The numbers between tools do not agree. Canopy's path is structurally simpler and more invasive than the standard stack. Both the visitor capture and the conversion capture share the same destination: a table inside the buyer's own database, written to by routes inside the buyer's own deployment. Every event lives there, the visitor's first arrival, the pages they viewed, the click events that crossed the conversion boundary, the form submissions, the scan reports, the deals created from those records, all in the same database. There is no SDK loaded from a third-party CDN; the capture script is served from the buyer's own domain. There is no third-party tracking cookie; the identifier is a first-party cookie scoped to the buyer's site. There is no event upload to an external data center; the events POST to a route inside the buyer's deployment that writes them straight to the buyer's database. Bot pressure is separated from real visitors at the ingest layer. This is the part most analytics dashboards either over-count, inflating vanity numbers that make the buyer feel good and decisions worse, or under-count, hiding a real signal about scraper attention or scrape-driven cost. Canopy classifies traffic at the moment of capture using a combination of user-agent matching, behavioral fingerprinting, and a watchlist of known automation infrastructure. The classification writes to the same row as the event, so the headline numbers in the dashboard reflect actual potential customers while the bot pressure stays surfaced in the underlying data when the buyer wants to look at it. Both numbers are honest; they just show up in different places. A buyer who is trying to make a marketing decision sees the human-traffic numbers; a buyer who is debugging an unusual cost spike or an unusual bounce rate can drill into the bot view in the same dashboard. Real-user Web Vitals are captured from the buyer's own site and posted to the same database. Largest Contentful Paint, Interaction to Next Paint, Cumulative Layout Shift, Time to First Byte, First Contentful Paint, all measured on every real visitor session and stored as event rows. The dashboard renders the per-percentile distributions, the per-page breakdowns, and the regression timeline against deploys. When a regression shows up after a deploy, the buyer can answer 'is this real or just bot pressure' against the same database that holds pipeline. They can also answer 'is this regression hurting conversion' in the same dashboard, with the same numbers, against the same auth gate. No browser-tab switching. No quarterly meeting about whose numbers agree. Search insight enters the same database through a daily ingest from the buyer's Search Console property. Impressions, clicks, average position, the queries the buyer's site is showing for, all attributed to the pages they landed on. The query data joins to the visitor data on the landing-page key, and the landing-page data joins to the deal data through the standard funnel attribution. The buyer can ask 'which queries produced visitors who became deals' in a single SQL question because all the rows live in the same database. The answer is at the same trust level as the rest of the analytics, which is to say the buyer can audit it, query it, modify it, replicate it. The honest exclusion: Canopy is not built for systems with billions of events per day. The architecture assumes the buyer is doing thousands to tens of thousands of events per day, where architectural ownership matters more than horizontal scale. At the very high end of event volume, the right answer is a dedicated event pipeline, a streaming aggregation layer, a separate analytics database optimized for OLAP queries, and a different team to operate it; that is a different product and a different price. The trade-off Canopy is taking is the one that fits a small business with revenue, conversion data, and the appetite to ask precise questions about what is producing the revenue. It is not the trade-off for a high-volume consumer SaaS. A second honest exclusion: privacy posture is first-party-only by design. There is no third-party tracking cookie, no cross-site identifier, no shared identity graph with other Canopy installs or with the studio. Each install's visitor data stays in that install's database. Raw IP addresses are not persisted; the geolocation derived from the IP at the moment of capture is persisted, but the IP itself is dropped after that derivation. This stance is partly about defensibility under privacy regulation, partly about not surprising the buyer when they look at what is in their database, and partly about the fact that I do not need cross-site identity to answer the questions Canopy is built to answer. The dashboard reads from already-aggregated views rather than from the raw event tables on every render. Aggregations refresh on a schedule that fits the freshness requirement of each kind of question: visitor counts every few minutes, Web Vitals percentiles hourly, source-to-deal joins overnight. The dashboard stays fast even as the underlying data grows, because the aggregated views grow much more slowly than the event-row tables do. The buyer's database does not have to be infinitely fast at OLAP queries; the dashboard's read paths are designed around the assumption that the database is normal-good rather than analytical-grade, which is the right assumption for the price tier this is in. The operational consequence is the one the architecture targets: when a regression shows up after a deploy, the buyer can answer 'is this real or just bot pressure' against the same database that holds pipeline, in the same dashboard where they review deals, behind the same auth wall. The marketing question, the performance question, and the conversion question are answered by the same numbers in the same place. There is no quarterly conversation about which tool's bounce rate is right because there is only one tool. There is no integration to break because there is no integration. The data is the buyer's, and the questions the data can answer are bounded only by the SQL the buyer is willing to write.