Pipeline & Relationships
Deal-stage primary, the audit log as the system of record, contact timeline auto-aggregated across every interaction the buyer has ever had with that person. Why the source-of-truth question shapes everything, why I rejected contact-status-as-primary, and what the data lets a team do that a typical CRM does not.
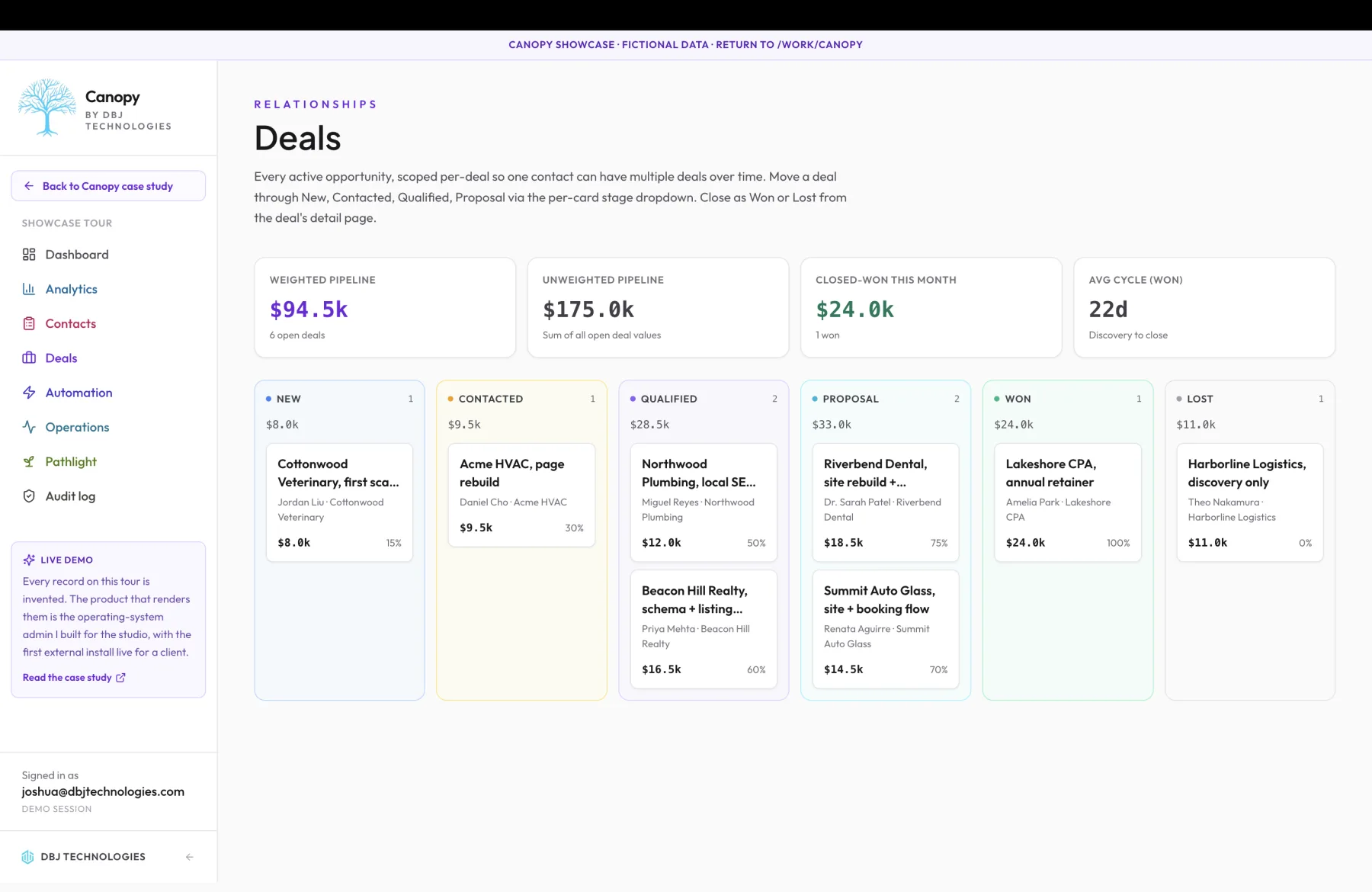
The question that drives the data model: what does it actually mean to say a CRM is 'the source of truth.' For most small-business CRMs, the answer is 'whatever the most recent person to touch the record typed in.' That is not truth; that is the latest belief held by whichever team member happened to be the last edit. Two days later, when the team is trying to remember whether the deal moved to proposal because the prospect's CFO signed off or because nobody updated the record after a stalled call, the latest-belief model produces the wrong answer to the only question that matters: what actually happened. A CRM that cannot tell you what happened, only what was last typed, is a worse-than-useless mirror of the team's own forgetfulness. Canopy treats truth as the audit log. Every meaningful change to a record writes a before-and-after snapshot attributed to the operator who made the change, with a timestamp and the action or rule that produced it. The current state of any record is the projection of those events, the way you would compute a current account balance from a sequence of bank transactions. The implication is that the database can answer questions the team did not know to ask when they wrote the record, because the events are still there to replay. 'When did this deal first enter the proposal stage' is a query against the audit log, not a guess based on the field's current value. 'Who was the operator on the last three changes to this contact's status' is also a query. The answers are queryable, attributable, and exportable, and they are the same answers two weeks later as they were today. I considered making contact status the primary axis of the data model, with deals as derived fields on the contact. That is the shape most small-business CRMs use because it is the simpler relational design: each contact has a status field, the status changes over time, and the team's view is contact-shaped. I rejected it for a reason any business with repeat customers will recognize. A contact whose first deal closed-won six months ago and whose second deal is currently in proposal cannot be expressed as one status field. The contact-shaped model collapses to whichever deal is most recent and silently drops the prior history. In a recurring-relationship business that prior history is exactly where the next sale lives, so the model has to keep it visible rather than fold it away. So deals are primary, and contact status is a denormalized mirror of the contact's primary current deal stage, kept for backward compatibility with the old shape, but not the source of truth. The mechanism for the deal-stage primary model is straightforward in shape: deals are first-class entities with their own stage transitions, their own probability percentages, their own values, their own timelines. A contact has many deals over time. The pipeline kanban board reads deals, not contacts; the columns are deal stages, the cards are individual deals, and a contact with three open deals shows up as three cards in three columns. The probability rollup is per-deal-stage with per-deal weighting, which is the right unit of forecasting because two deals at twenty-five thousand dollars each in proposal at seventy-five percent probability tells the buyer something the contact-stage model cannot. The contact detail view assembles itself. Whatever the buyer's team has ever done involving a given person flows onto one timeline without anyone having to copy it there. Form submissions land as records; email replies are pulled in from the buyer's email account through an authenticated integration; scan reports attach when the contact's domain is scanned; calls logged through the call modal arrive as events; notes added through the contact UI write to the same timeline; deal-stage transitions for any deal owned by the contact also surface there. Nothing has to be manually copied between systems because there are no other systems. The timeline is event-shaped, ordered by time, with each event keeping its provenance so the buyer can ask 'how did this email reach me' and get a real answer instead of 'we synced it from somewhere.' Bulk actions cover the cases where individual record edits do not fit the operator's intent. Move ten deals from contacted to qualified at once. Tag fifty contacts as a Q3 outreach cohort. Reassign a list of contacts to a different operator. Each bulk action writes a single audit-log entry with the affected record IDs and the change applied, so a question like 'who tagged these fifty contacts and when' has a definitive answer. Bulk actions are deliberate, traceable, and reversible by design. Keyboard navigation works the way an operator who lives in the tool every day expects it to work. The pipeline kanban has keyboard shortcuts for moving deals between stages, navigating between cards, opening the deal detail view, applying bulk selections. The contact list has a command palette that supports fuzzy-search across every contact and deal in the database. The expectation is that an operator should be able to live in Canopy without touching the mouse for an hour at a stretch, the way operators live in their email client and their text editor. Most CRMs do not pay this discipline because their primary market is decision-makers reviewing dashboards rather than operators executing day-to-day work. Canopy's primary market is the operator. The pipeline forecasting rolls up at multiple granularities. Per-stage weighted forecast across the whole pipeline; per-operator forecast for a sales team; per-time-window forecast for cohort analysis. The weights are configurable per install because every business's stage probabilities are different. A productized engagement with a long discovery cycle will have proposal probabilities that look nothing like a fast-moving e-commerce product's, and the weights should reflect the buyer's actual close rates rather than a vendor's defaults. The audit log is also where regret-protection lives. If an operator marks a deal closed-lost and a week later realizes the prospect actually came back and signed, the audit log holds the previous state and the deal can be restored to its prior position with the audit-log entry recording the restoration. The restoration is itself an event in the audit log, so the question 'what really happened to this deal' produces a complete history rather than a pretendable-clean current state. This is the practical value of event sourcing: not just attribution of changes, but reversibility of changes, and a complete chronicle the buyer can audit. The honest framing on what this is not: Canopy's pipeline surface is built for small businesses with under five hundred active deals at a time, where the operators have the time and the discipline to update records. It is not a sales-engagement platform with auto-dialer integration and AI-generated follow-up suggestions; that is a different product for a different scale. The buyer who needs that scale is past the size where Canopy is the right fit, and that is fine; the architecture's honest exclusions are part of the design, not an apology. The operational consequence the buyer feels is portability. A team member leaves, the database stays. A new operator joins, the audit log already explains what the previous team did and why. The questions are queryable, the answers are verifiable. The export, if one ever happens, is the buyer's database itself, in its native shape, on infrastructure the buyer pays for directly. The team can leave whenever they like and take the whole pipeline with them, because the pipeline was always theirs.